
對於高成長跟中大型客戶 ,數據量不停的成長,非常需要可以擴充Scale out的檔案系統.當然不可能很單純的多買陣列櫃.
Scale out是指能夠橫向添購Server,增加使用空間.增加效能.
因此就有了DFS (Distributed file system) 分散式檔案系統.可方便橫行擴充與實時擴充檔案系統容量.
開源的DFS 目前主流有Hadoop Distributed File System (HDFS) , GlusterFS ,Ceph, Lustre,Moose ,Manila.
但當這類大型DFS系統掛掉時候,資料怎辦? 常規的方法如果都不行了
這需要
1.熟悉這類DFS infra架構.
2.可閱讀原始碼來解析檔案系統
3.能夠自行改編寫mount這些DFS檔案系統
才能恢復大數據資料
以下是客戶 Lustre資料救援案例
總共8台機器
二台MDS (Metadata Server)
六台OS (Object Storage Target)
每node:
16 PCS 2TB 硬碟
Raid卡:LSI Raid 5
本機上的 Raid Pool Filesystem :ldiskfs (可用ext4,ext3)
先進入LSI Storage Manager 發現客戶硬碟離線

客戶因為某node 2顆硬碟離線 造成陣列損壞 無法掛載
讓整個Lustre系統 無法掛載
這種大型儲存案子 第一部 就是先把每個硬碟都DD (全扇區備份)
很吃空間 但是這就是基本應該做的
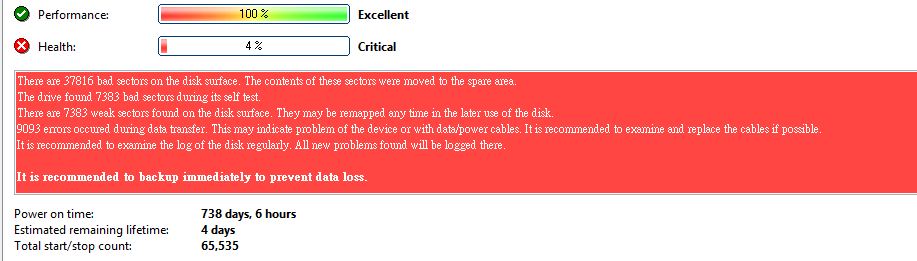
做扇區備份同時 發現有二顆硬碟有問題.
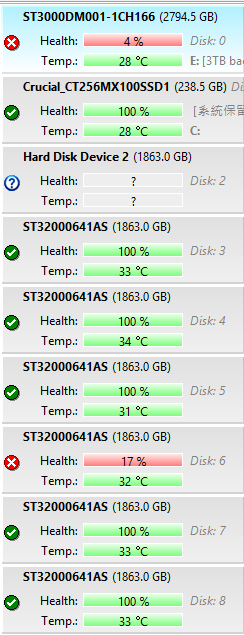
使用PC3000 設備將硬碟修復, 做資料鏡像

所有硬碟鏡像完畢後開始嘗試解析原始客戶檔案系統,很不幸的 客戶由於更換硬碟過度,原硬碟順序都錯亂.
因此要自行解析ldiskfs filesystem .找出16顆陣列硬碟順序排列,Strip size,陣列走向
Raid狀態組好 Lustre ost目錄架構從現
drwxr-xr-x 2 root root 4096 Sep 29 10:12 CONFIGS/
drwx—— 5 root root 4096 Nov 7 2013 O/
-rw-r–r– 1 root root 4096 Nov 7 2013 health_check
-rwx—— 1 root root 20864 Nov 7 2013 last_rcvd*
drwx—— 2 root root 16384 Nov 7 2013 lost+found/
. /CONFIGS 目錄:
-rw-r–r– 1 root root 8880 Sep 29 10:12 chome-OST0008
-rw-r–r– 1 root root 12288 Nov 11 2013 mountdata
/O 目錄:
drwx—— 34 root root 4096 Nov 7 2013 0/
drwx—— 2 root root 4096 Nov 7 2013 1/
drwx—— 2 root root 4096 Nov 7 2013 2/
4. /O/0 目錄:
-rwx—— 1 root root 8 Nov 7 2013 LAST_ID*
drwx—— 2 root root 561152 Jan 22 11:10 d0/
drwx—— 2 root root 548864 Jan 22 11:10 d1/
drwx—— 2 root root 593920 Jan 22 11:10 d10/
drwx—— 2 root root 552960 Jan 22 11:10 d11/
……………………
drwx—— 2 root root 552960 Jan 22 11:10 d9/
將客戶單座ost1 資料回覆融入到 原有Lustre檔案系統

盡可能的將客戶幾年的心血運算180TB 大數據都保留了.
怎麼做可以避免這樣的問題發生,或是真的發生了該怎樣解,或是減輕費用的支出,我們歸納出幾個要點:
1. 備份的策略要更完備
DFS很方便,可以盡量擴充,但是還是要想盡辦法備份,或是壓縮備份,一定要做災難演練。
2. 資料恢復手段只能留做最後手段,但當災難發生時候 如果發現備份的資料不對 或是太舊 若想要保有原資料請盡量保持原儲存裝置狀況,不要自行做任何處理,
像是新增或修改LUN, FSCK Rebuild ,或某些KB 方法等 動到檔案層結構都有風險,要做這些動作前,請先對最底層Storage做快照,無法快照就要對Storage Pool做DD (鏡像全部扇區),
不然自行處理過後,會大幅度拉高資料救援成本並可能造成救回的資料再也無法挽回。
3. 要找怎樣的資料救援公司,在這個案例中,至少要有以下幾個要點:
- 要有完整的設備:
硬碟救援設備 PC3000 MRT 完整硬碟材料庫 訂製光纖轉卡 10G 網路服務器 超大容量Standby Server 各種虛擬化實驗室(Vsphere,kvm,Hyperv等)
最專業的處理每個層面儲存裝置的問題。 - 了解陣列、檔案系統結構、虛擬化架構 、分散式檔案系統架構:才能第一時間的處置跟該救援什麼樣的資料,也才能對未公開檔案格式(如VMFS)做逆向推測 ,
最終要驗證救出來的資料是否可用…等。 - 受過專業援技術訓練 目前OSSLab為台灣唯一有下面資料救援證照公司.




